
3rd January 2022
Since I returned back home in Italy, aside for dealing with the crazy Covid situation, I had some time off to read some documents and deepen some concepts that were in my personal list since some time ago…
Indeed, multiple side projects have accumulated during the writing of the new Windows Internals book (like learning Rust, Spanish, and so on…). The book is now available, so I finally ended up having some free time (after three long years). One of the interesting project that I had was to deepen the new CPU technologies present in the new Alder Lake processors (which, kindly enough, Intel provided me a sample).
It seems that Intel had published a long and detailed paper describing all the new instructions and features of the Alder Lake and Sapphire Rapids processors. The document is available here: https://www.intel.com/content/www/us/en/develop/download/intel-architecture-instruction-set-extensions-programming-reference.html. So in the endless flight from Seattle to Italy I was able to read it entirely 😁.
Let’s start by saying that a lot of new features have been brought by the new architecture (which, in my tests, is super fast), like the Advanced Matrix Extensions (AMX), Process Address space identifiers (PASIDs), Architectural Last Branch Records (LBRs), Enhanced Hardware Feedback Interface and so on… I will skip a lot of them (readers should refer to the above document for gathering all the needed information), but I want to describe two features that in my opinion are really cool and useful: “Virtualization Technology Redirect Protection”, also known in the field as HLAT, and “User Interrupts”.
Let’s start with the Virtualization Technology Redirect Protection (from now on abbreviated as VT-rp)…
Intel VT-rp
After the introduction of the Shadow Stack in the 11th generation CPUs (Tiger Lake), there was still just a weak point that needed enhanced hardware protection, the possibility of an attacker to be able to remap one or more protected memory pages, simply by writing in the kernel page tables. The system has no way to prevent an exploiter to write in the page tables, and even Hyperguard (as described in the good article that Yarden recently publishes) is not totally able to non-deterministically protect against this kind of remapping (I will leave the details to her, I am not allowed to talk about PG/HG).
Furthermore, protecting the page tables through the EPT in the Hypervisor is not possible either, simply because the CPU always write to those pages (when performing the page table walking). In case the EPTs describing the guest page tables is mapped with read-only access, every CPU access would cause a VMEXIT. This simply mean that the performances would have been catastrophic (VMEXIT is a slow operation)….
So, here is where the VT-rp technology comes to rescue 👌😯🍕….
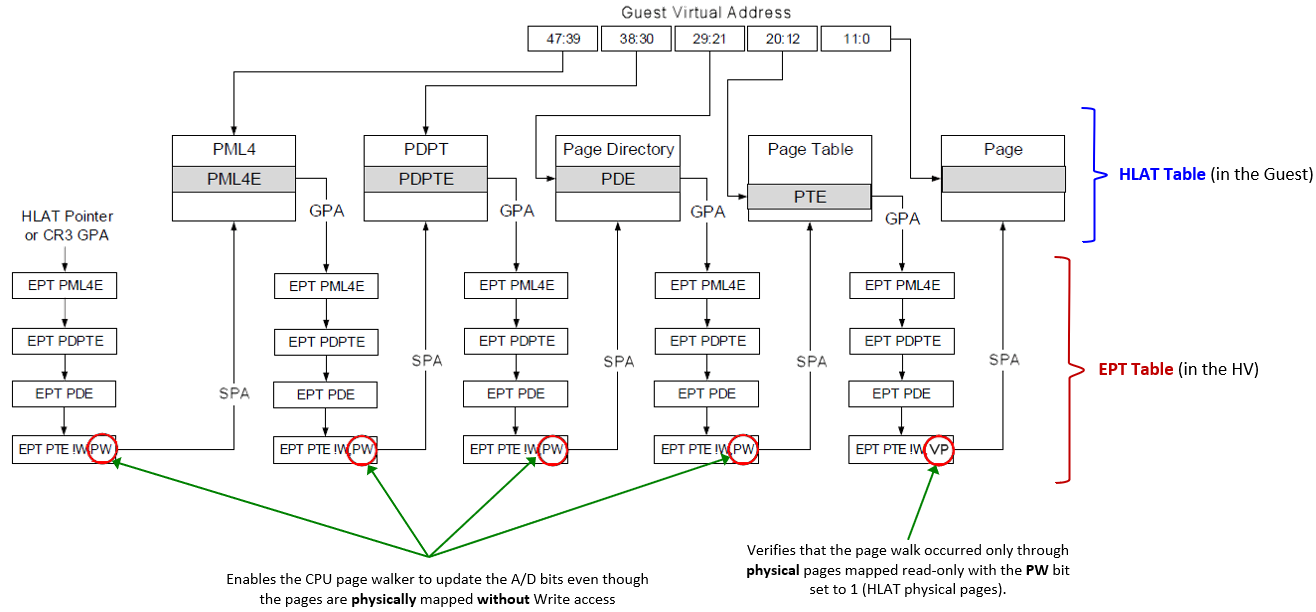
In Intel VT-rp indeed, the Hypervisor (VMX root) supports new tertiary processor-based VM-execution controls, which can be used to enable the HLAT (Hypervisor-managed Linear Address Translation), Paging Write (PW) and Verify Paging-Write (VP) bits in the Extended Page Tables (EPT). VT-rp is so implemented in two pieces:
- In the EPT tables, used by the Hypervisor to translates Guest Physical Addresses (GPAs) to System Physical Addresses (SPAs). This procedure is normally referred as Stage-2 translation. Remember, while EPTs controls the physical translation, regular page table controls the virtual translation (GVA to GPA).
The leaf EPT pages can now have the Paging Write (PW) bit (58) set to 1 to allow the processor page walker to write the A/D (Accessed / Dirty) bits even though the physical page is mapped without Write permission (in the EPT).
Note that the PW bit can be used to enforce that a GVA is forced to be bound to a specific GPA, but can’t do anything to prevent the same GPA to be remapped by another guest linear address. So, another bit in the leaf EPTs have been designed: when the Verify Paging-Write (VP, to not be confused with PW) bit (57) is set to 1, the processor page walker verifies that all the physical page tables used for translating the GVA have all the PW bit set to 1 in the EPT.
- A new HLAT table is mapped in both the Normal and the Secure Kernel, which will assist the processor for translating privileged memory pages. A new 64-bit control field, “Hypervisor-managed Linear Address Translation Pointer” is defined in the VMCS data structure managed by the Hypervisor. This field point to the GPA of the HLAT table.
An HLAT table is identical to the standard 4 (or 5) level paging structure used in VMX non-root mode to translate virtual addresses to physical addresses, except for a little differences. There is a new “Restart” bit (#11) that allow the page walker to stop the walk and restart from the regular (CR3-rooted) ordinary paging structure managed by the guest OS.
Note that the entire HLAT table is physically mapped through the EPT in the Normal kernel with read-only privileges, but with the PW bit set to 1. In that way the CPU is able to update the A/D bits of its entries, but no software entity would be ever able to modify its content. Only the Secure Kernel will be able to modify its content, because the HV usually uses another EPT to physically map the HLAT in the Secure Kernel. In this case the EPT will have full RW access rights.
Putting together all the pieces of the puzzle – How this black magic works
In the new configuration, when the “Enable HLAT” VM execution control is set to 1, the processor translates a guest virtual address in a different way: in case it is instructed to do so by some new Protected Linear Range (PLR) registers (which stores the number of most significant bits that should be set to 1 in the address for being translated by HLAT), the CPU start the GVA to GPA translation using the HLAT (and not the CR3 register).
The HLAT manages the final translation. It can contain all the page table hierarchy needed to return the final guest physical address (in that case no regular page tables are ever consulted) *or* it can happen that a entry in any hierarchy can set the “Restart” bit to 1. This obliges the processor to restart the translation from the regular guest paging table structure, addressed by the CR3 register in the guest.
This allow a fine-grained protection of the VA translation, and will prevent the possibility of attackers to remap the VA to another physical address (a feature very useful for KDP for example, as explained in my previous article). Note that the EPT still controls the physical translation: a discussed, an attacker can not even remap the GPA to another VA thanks to the VP bit applied into the EPT, because the page walker in that case will verify that the GVA is translated only by HLAT entries (which have PW bit set to 1), preventing any other possible remapping.
I know that is confusing at the first glance, so here is an amazing picture taken from the Intel manual and enhanced by my amazing Excel drawing skills™:
Curious readers would ask if Windows already implements HLAT. The answer is “we are working on it”… How? Of course I can not say a lot but, if you are a Windows Internals enthusiast, we are trying to replace the NTEs in the Secure Kernel with a new format that the hardware (HLAT table) will understand…
This will definitively raise the bar of the overall system security. So as usual, Stay tuned! 😲
Update of 1/10/2022
User Interrupts
Another cool feature of Alder Lake in my opinion is certainly User Interrupts. As the feature’s name explicitly says, it is the capacity of the CPU to deliver a interrupt to user-mode software executed in CPL 3, without any change to the segmentation state.
User-mode interrupts are enabled only if a new bit in the CR4 register, the UINTR bit (25), is set to 1. There are 64 possible different user-interrupts vectors, which are mapped by a single bit in a new UIRR (User-Interrupt Request Register, which is actionable thanks to the IA32_UINTR_RR MSR – 0x985). In Intel nomenclature, the UIRRV is the position of the most significant bit in the UIRR, which means that is the current User-Interrupt Vector.
It should be clear to the reader that each bit in the UIRR corresponds to a User-Interrupt vector (which is a very different concept in respect to regular interrupt vectors) There are multiple way in which a CPU or software can deliver a user-interrupt, which happens only when the CPU is executing user-mode code:
- Kernel software writes in the CPU UIRR, or perform an XRSTORS that store new bits in it. In this case, when the processor returns to user-mode (via standard means, like a trap return or service call return), and if CR4.UINTR = 1, it performs the User-Interrupt Delivery and the CPL 3 code execution is diverted to the User Interrupt Handler, defined in the IA32_UINTR_HANDLER (0x986) MSR. There are multiple rules regarding how the stack is prepared by the hardware, which are similar to kernel interrupt dispatching, and I am not going to deepen here (the Intel manual is very clear and detailed about that.
- A software operating in kernel mode on another CPU can perform User-interrupt posting by sending an ordinary interrupt (via local APIC) to a target processor on a vector described by the UINV register (User-Interrupt notification vector), which is accessible via the bits [39:32] of the IA32_UINTR_MISC (0x988) MSR. At this point the processor executes a procedure called “User interrupt notification” (this part is a bit tricky to understand from the Intel manual). The procedure’s goal is to set the relative bits in the target processor’s UIRR starting from the User-posted-interrupt descriptor (UPID), that the kernel software sets before sending the ordinary interrupt. The UPID is indeed accessible via the IA32_UINTR_PD (0x989) MSR and is also heavily used by the SENDUIPI new instruction (see below). In bits [127:64] it contains the Posted-interrupt request (PIR), which is the 64-bit mask that will be copied in the target processor’s UIRR. The delivery of the interrupt then follows the same pattern as the previous case.
- A software executing in user mode can send a user-interrupt to another CPU by using the new SENDUIPI instruction (the only one that can be executed in CPL 3. Even this part of the Intel manual is a little messy in my opinion). A user-interrupt target table (UITT) must be previously set by the kernel by interacting with the A32_UINTR_TT (0x98A) MSR. The table is made of 16-bytes (128 bit) entries, where an entry is composed of: a valid bit, the ordinary notification interrupt vector (0 to 255) (this is similar to the UINV) and the address of a UPID, similar as the previous case. So callers of the SENDUIPI instruction in user-mode should just specify a register containing the ID in the user-interrupt target table. The instruction then identifies the correct entry in the table, and, if the entry is valid (note that otherwise a #GP fault is generated), the CPU writes the relative bit in the posted-interrupt request bitmask of the UPID and send an ordinary interrupt using the vector described by the “Notification vector” field of the UITT entry. The latter will be dispatched as the previous case.
As the reader can see, the architecture is a little complex. Luckily enough, the Intel manual explains all the little details. When a user-interrupt fires, a particular ISR routine in the target process address space is executed, with the stack ad-hoc prepared by the machine (as for regular interrupt). The User ISR will be executed by the machine with the User Interrupt Flag (UIF) clear (set to 0). This flag, which is not mapped in any MSR (but strangely enough is saved or restored by XSAVE / XRSTOR), can be set or clear by user-mode software using the new STUI and CLUI instructions. Furthermore, when the user-interrupt ISR returns via the new UIRET instruction, the machine automatically set the UIF back to 1 (no User interrupts are delivered when UIF is 0).
This has the important implication that User Interrupts, similar to the ordinary ones, follow some nesting rules (a little different from regular interrupt though, where the IF is set / clear depending on the type of the gate descriptor in the IDT). This is definitively something that the application developer should keep in mind.
Potential usage in Windows or Other OSs
One thing that I still have not fully understood is the usage model that Intel had in mind when developing the User Interrupts feature. As careful readers may have noticed, the underlying OS should heavily implement support for User Interrupts to make them work, especially in the scheduler, which should at least save / restore all the involved MSRs when switching between threads of different processes (they may have different supports for user-interrupts). Not counting the fact that the OS kernel should provide facilities to manage user-interrupts vectors per process.
As Windows Internals enthusiasts (who have read my book 😁) know, Windows already support a software technology which achieves more or less the same: Asynchronous Procedure Call (APC). APCs can be dispatched while the target thread is already executing Kernel mode code (via an APC interrupt, which dispatches a Special Kernel-mode APC), or while the target thread has been pre-empted (via a Normal kernel-mode APC). More important, the OS supports also User APCs (Special and Normal), which are dispatched before the OS is returning to User mode and fully executed in CPL 3 (malware analysts know this a lot… right? XD).
So, to me it is not fully clear the scenario by which User Interrupts can be useful here. Maybe just in highly contended and high priority threads, where the round-trip to kernel mode can be very expensive (remember, User Interrupt dispatching is executed entirely by the machine, which means that when thread A want to send a User IPI to thread B, it should not go to Kernel mode, unless thread B is not being executed of course). Furthemore, user Interrupts are fully compatible with Virtualization, so I think that in this scenario they can be useful (maybe it would be a good idea to empower User APCs???).
Again, if a reader knows more please let me know 😊….
Conclusions
It is very nice to see a lot of new features coming in this new generation of Intel processors, which will help a lot also in maintaining a new level of Security. I am not an exploiter, but I am wondering how with CET + HLAT an attacker will be able to exploit the system (probably with Data-driven attacks, but if you know more please send me a private message). We will see how other CPU manufacturers will respond with their own technologies. Furthermore, I have also no idea how and when Linux-based OS would be able to use the new technologies….
That is all for now folks!
Now it is time for me to return to Seattle 😁….
[…] Allievi for Alder Lake and the new Intel Features, as well as answering a few […]